Web-Scrapping Part -I
Now, if we are about to get started on the subject let’s just get our objectives and technical terms straight. Web-scrapping(it’s a legitimate subject, by th way) simply means to scrap the contents of a web-page by looking at its html(more on that later). So. a couple of things are probably bugging you about this overly simple thing, right?
Why should I care?
And there is an equally simple answer for it too.
Machine learning is all about data and it can be sometimes immensely helpful to be able to gather data and create one’s own datasets for testing the model or just adding data to it in general!! But then, why write the code when we can just copy and paste things? In fact, the example today is simple enough to make you want to do that. Resist the temptation though. It’s not possible to do so for bigger datasets with billions of columns. So, without delay, let’s get started.
This time we take the help of two python libraries:
- bs4(for web-scrapping)
- requests(for fetching the webpage from the site)
Both the libraries can be installed using:
pip install bs4
pip install requests
And we are good to go!!!!
Import the libraries using:
from bs4 import BeautifulSoup
import requests
Let’s get started.
At first we mention the url of the web-page we want to visit and call the requests library to fetch the contents of the web-page for us. The page variable stores the response.
url="https://blackadderquotes.com/blackadder-series-4-episode-1-captain-cook-full-script"
page= requests.get(url)
page
This should give a response of status 200 meaning that everything has gone on well and without any sort of trouble.
Let’s get our hands dirty with some web-scrapping then
soup= BeautifulSoup(page.content, 'html.parser')
soup
This should return all the html content of the page. In fact, you can go to the settings of the page, then Developer tools, then elements to verify that all of the html has indeed been copied from there. But why do we need the entire contents? All we need is some selective portion of the data and have it to ourselves in an understandable format. As an example we will use today the web-page whose link was mentioned in the url.
The website contains the full script of an episode of a world famous sitcom, Blackadder, starring Rowan Atkinson, who is more famous as Mr. Bean!!. It’s golden comedy that’s what it is!!! The four seasons are based on four stages of the British history, thereby making it ideal for natural language generation purposes, character analyses and several amusing things you can already find on kaggle, both datasets (of Harry Potter and Friends) and notebooks alike.
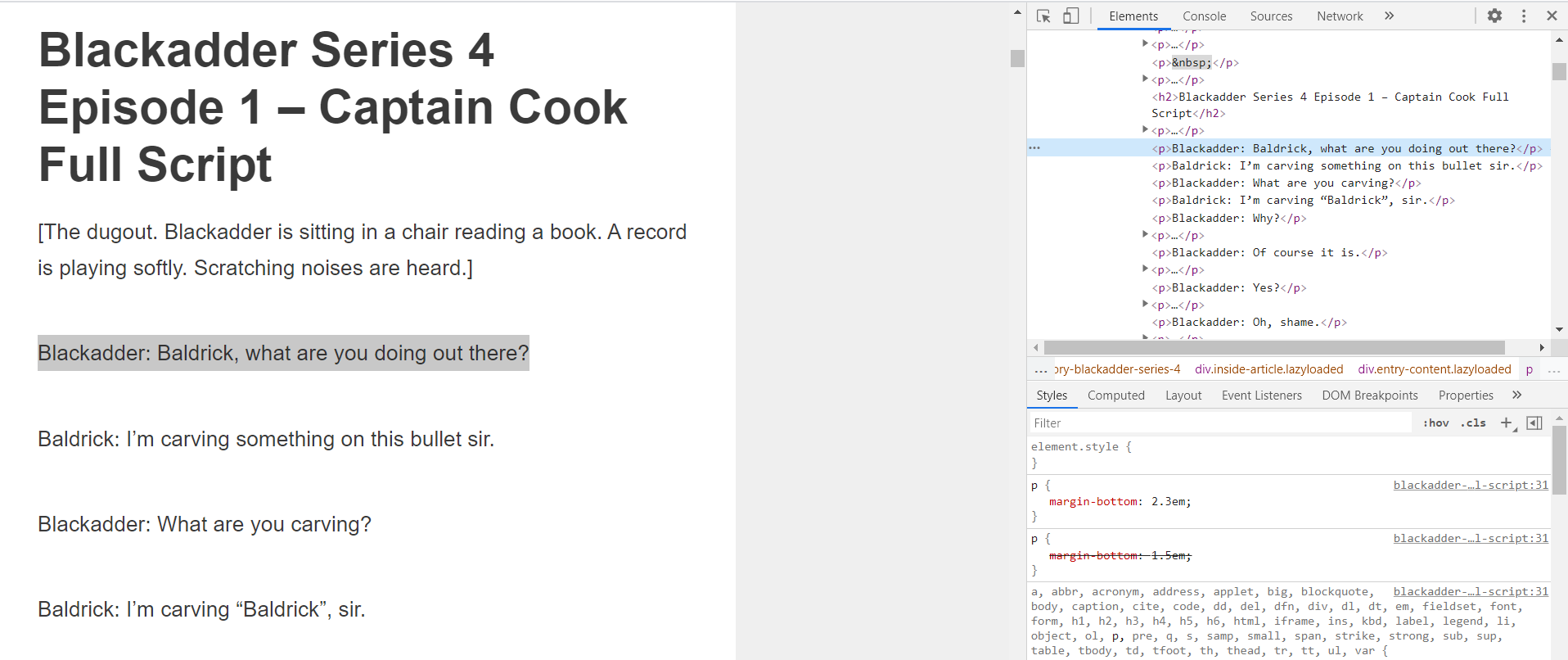
Do you see the above picture? Look at the console and you will find that the immediate parent of the <p> is a div with a class =”entry-content lazyloaded”. We want the text written in those <p> tags. We express such a wish in this format.
script=soup.select('div.entry-content p')
script
This should load the entire html of the page and that’s neither clean nor pretty….
We are pretty near there but not done yet. There are a lot of images in the script too. The get_text() extracts the text from the tags.
dialogues=[]
for i in script:
dialogues.append(i.get_text())
dialogues
And we assemble them together
file1 = open("Season 4.txt","a+")
for dialogue in dialogues:
dialogue=dialogue.rstrip("\n")
file1.write(dialogue)
file1.write("\n")
file1.close()
So, that’s just one episode done. We can do similarly for the others too. But congrats on the first dataset
- The full notebook is here in case you want to play around with it a bit.
- The dataset I created is here at Kaggle.
Web-scrapping Part - II
“When the going gets tough the tough gets going.”
The second website is a little trickier to work on. But we can get through this.
import requests
from bs4 import BeautifulSoup as bs
url = "https://www.amazon.in/Test-Exclusive-746/product-reviews/B07DJHXTLJ/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
page = requests.get(url)
soup = bs(page.content,'html.parser')
The end result should be something like this:
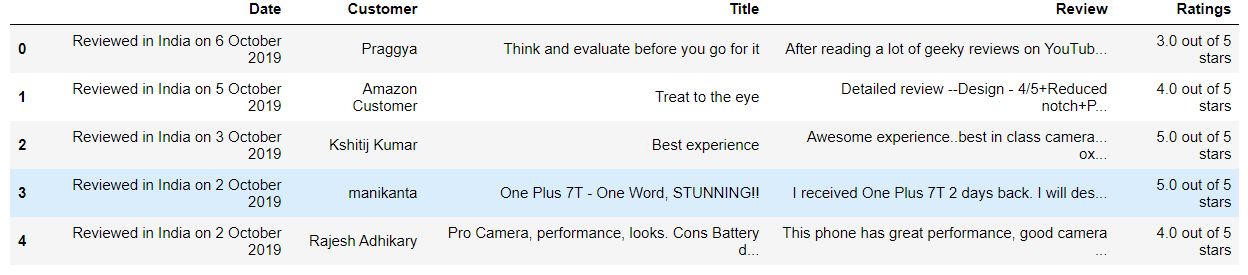
Give it some thought before moving on.
Now, let’s get the list of names first, shall we? Here is the slight change of syntax that will enable you to do so.
name=soup.select('div span.a-profile-name')
name
data= name[2:]
data
If you would click on the console again, you would find out that the div which encloses the names has a child span of the class “a-profile-name”. So, the general syntax find the parent tags and keep on adding children to it. But the data we get from there is hardly clean. if would notice the first entry is of amazon and the second entry is the one written at the top of the page in the extract. The third entry infact is the exact copy of the previous one as it is part of the original content. So we need to drop them.
cust_name=[]
for i in data:
cust_name.append(i.get_text())
cust_name
And that should get the full list of customers who have left their reviews.
Similarly,
ratings=soup.select('div.a-row i.a-icon span.a-icon-alt')[3:]
ratings
data=[]
for i in ratings:
data.append(i.get_text())
title=soup.select('a.review-title span')
rev_title=[]
for i in title:
rev_title.append(i.get_text())
rev_title
date=soup.select('span.review-date')
rev_date=[]
for i in date:
rev_date.append(i.get_text())
content=soup.select('span.review-text-content span')
rev_content=[]
for i in content:
rev_content.append(i.get_text())
But wait are the lengths of the lists same for everyone of those. Let it remain a puzzler as to what to do if they are not the same.
And finally,
import pandas as pd
df= pd.DataFrame()
df["Date"]= rev_date
df["Customer"]=cust_name
df["Title"]=rev_title
df["Review"]=rev_content
df["Ratings"]=data
df.to_csv("Reviews.csv")
That’s it. Some final exercises could be to run the final scripts and see the output.
html=list(soup.children)
soup.find('p')
p=soup.find_all('p')
Until the next post.🖐